

This is the technology worth trillions of dollars huh
Well, it’s almost correct. It’s just one letter off. Maybe if we invest millions more it will be right next time.
Or maybe it is just not accurate and never will be…I will not every fully trust AI. I’m sure there are use cases for it, I just don’t have any.
Cases where you want something googled quickly to get an answer, and it’s low consequence when the answer is wrong.
IE, say a bar arguement over whether that guy was in that movie. Or you need a customer service agent, but don’t actually care about your customers and don’t want to pay someone, or your coding a feature for windows.
Chatbots are crap. I had to talk to one with my ISP when I had issues. Within one minute I had to request it to connect me to a real person. The problem I was having was not a standard issue, so of course the bot did not understand at all… And I don’t need a bot to give me all the standard solutions, I’ve already tried all of that before I even contact customer support.
The “don’t actually care about your customers” is key because AI is terrible at doing that. And most of the things rich people as salivating for.
It’s good at quickly generating output that has better odds than random chance of being right. And that’s a niche, but sometimes useful tool. If the cost of failure is high, like a pissed off customer, it’s not a good tool. If the cost is low or failure still has value (such as when an expert is using it to help write code, and the code is wrong but can be fixed with less effort than writing it wholesale).
There aren’t enough people in executive positions that understand AI well enough to put to good use. They are going to become disillusioned, but not better informed.
Isnt checking if someone was in a movie really easy to do without AI?
Just one more private nuclear power plant, bro…
They’re using oil, gas, and if Trump gets his way, fucking coal.
Unless you count Three Mile Island.
There were plans from Google and Microsoft to build their own nuclear power plants to power their ever-consuming data centers.
The letters that make up words is a common blind spot for AIs, since they are trained on strings of tokens (roughly words) they don’t have a good concept of which letters are inside those words or what order they are in.
It’s very funny that you can get ChaptGPT to spell out the word (making each letter an individual token) and still be wrong.
Of course it makes complete sense when you know how LLMs work, but this demo does a very concise job of short-circuiting the cognitive bias that talking machine == thinking machine.
I find it bizarre that people find these obvious cases to prove the tech is worthless. Like saying cars are worthless because they can’t go under water.
Not bizarre at all.
The point isn’t “they can’t do word games therefore they’re useless”, it’s “if this thing is so easily tripped up on the most trivial shit that a 6-year-old can figure out, don’t be going round claiming it has PhD level expertise”, or even “don’t be feeding its unreliable bullshit to me at the top of every search result”.
I don’t want to defend ai again, but it’s a technology, it can do some things and can’t do others. By now this should be obvious to everyone. Except to the people that believe everything commercials tell them.
How many people do you think know that AIs are “trained on tokens”, and understand what that means? It’s clearly not obvious to those who don’t, which are roughly everyone.
You don’t have to know about tokens to see what ai can and cannot do.
Go to an art museum and somebody will say ‘my 6 year old can make this too’, in my view this is a similar fallacy.
That makes no sense. That has nothing to do with it. What are you on about.
That’s like watching tv and not knowing how it works. You still know what to get out of it.
358 instances (so far) of lawyers in Australia using AI evidence which “hallucinated”.
And this week one was finally punished.
Ok? So, what you are saying is that some lawyers are idiots. I could have told you that before ai existed.
It’s not the AIs which are crap, its what they’ve been sold as capable of doing and the reliability of their results that’s massivelly disconnected from reality.
The crap is what a most of the Tech Investor class has pushed to the public about AI.
It’s thus not at all surprising that many who work or manage work in areas were precision and correctness is essential have been deceived into thinking AI can do much of the work for them and it turns out AI can’t really do it because of those precision and correctness requirement that it simply cannot achieve.
This will hit more those people who are not Tech experts, such as Lawyers, but even some supposedly Tech experts (such as some programmers) have been swindled in this way.
There are many great uses for AI, especially stuff other than LLMs, in areas where false positives or false negatives are no big deal, but that’s not were the Make Money Fast slimy salesmen push for them is.
I think people today, after having a year experience with ai know it’s capabilities reasonably well. My mother is 73 and it’s been a while since she stopped joking about what ai wrote to her that was silly or wrong, so people using computers at their jobs should be much more aware.
I agree about that llms are good at some things. They are great tools for what they can do. Let’s use them for those things! I mean even programming has benefitted a lot from this, especially in education, junior level stuff, prototyping, …
When using any product, a certain responsibility falls on the user. You can’t blame technology for what stupid users do.
A six year old can read and write Arabic, Chinese, Ge’ez, etc. and yet most people with PhD level experience probably can’t, and it’s probably useless to them. LLMs can do this also. You can count the number of letters in a word, but so can a program written in a few hundred bytes of assembly. It’s completely pointless to make LLMs to do that, as it’d just make them way less efficient than they need to be while adding nothing useful.
LOL, it seems like every time I get into a discussion with an AI evangelical, they invariably end up asking me to accept some really poor analogy that, much like an LLM’s output, looks superficially clever at first glance but doesn’t stand up to the slightest bit of scrutiny.
it’s more that the only way to get some anti AI crusader that there are some uses for it is to put it in an analogy that they have to actually process rather than spitting out an “ai bad” kneejerk.
I’m probably far more anti AI than average, for 95% of what it’s pushed for it’s completely useless, but that still leaves 5% that it’s genuinely useful for that some people refuse to accept.
I feel this. In my line of work I really don’t like using them for much of anything (programming ofc, like 80% of Lemmy users) because it gets details wrong too often to be useful and I don’t like babysitting.
But when I need a logging message, or to return an error, it’s genuinely a time saver. It’s good at pretty well 5%, as you say.
But using it for art, math, problem solving, any of that kind of stuff that gets tauted around by the business people? Useless, just fully fuckin useless.
I don’t know about “art”, one part of ai image generation is of replacing stock images and erotic photos which frankly I don’t have a huge issue with as they’re both at least semi-exploitative industries anyway in many ways and you just need something that’s good enough.
Obviously these don’t extend to things a reasonable person would consider art, but business majors and tech bros rebranding something shitty to position it as a competitor to or in the same class as something it so obviously isn’t.
it’s more that the only way to get some anti AI crusader that there are some uses for it
Name three.
I’m going to limit to LLMs as that’s the generally accepted term and there’s so many uses for AI in other fields that it’d be unfair.
-
Translation. LLMs are pretty much perfect for this.
-
Triaging issues for support. They’re useless for coming to solutions but as good as humans without the need to wait at sending people to the correct department to deal with their issues.
-
Finding and fixing issues with grammar. Spelling is something that can be caught by spell-checkers, but grammar is more context-aware, another thing that LLMs are pretty much designed for, and useful for people writing in a second language.
-
Finding starting points to research deeper. LLMs have a lot of data about a lot of things, so can be very useful for getting surface level information eg. about areas in a city you’re visiting, explaining concepts in simple terms etc.
-
Recipes. LLMs are great at saying what sounds right, so for cooking (not so much baking, but it may work) they’re great at spitting out recipes, including substitutions if needed, that go together without needing to read through how someone’s grandmother used to do xyz unrelated nonsense.
There’s a bunch more, but these were the first five that sprung to mind.
-
It’s amazing that if you acknowledge that:
- AI has some utility and
- The (now tiresome and sloppy) tests they’re using doesn’t negate 1
You are now an AI evangelist. Just as importantly, the level of investment into AI doesn’t justify #1. And when that realization hits business America, a correction will happen and the people who will be effected aren’t the well off, but the average worker. The gains are for the few, the loss for the many.
deleted by creator
So if the AI can’t do it then that’s just proof that the AI is too smart to be able to do it? That’s your arguement is it. Nah, it’s just crap
You think just because you attached it to an analogy that makes it make sense. That’s not how it works, look I can do it.
My car is way too technologically sophisticated to be able to fly, therefore AI doesn’t need to be able to work out how many l Rs are in “strawberry”.
See how that made literally no sense whatsoever.
Except you’re expecting it to do everything. Your car is too “technically advanced” to walk on the sidewalk, but wait, you can do that anyway and don’t need to reinvent your legs
Then why is Google using it for question like that?
Surely it should be advanced enough to realise it’s weakness with this kind of questions and just don’t give an answer.
They are using it for every question. It’s pointless. The only reason they are doing it is to blow up their numbers.
… they are trying to be infront. So that some future ai search wouldn’t capture their market share. It’s a safety thing even if it’s not working for all types of questions.
The only reason they are doing it is to blow up their numbers.
Ding ding ding.
It’s so they can have impressive metrics for shareholders.
“Our AI had n interactions this quarter! Look at that engagement!”, with no thought put into what user problems it actually solves.
It’s the same as web results in the Windows start menu. “Hey shareholders, Bing received n interactions through the start menu, isn’t that great? Look at that engagement!”, completely obfuscating that most of the people who clicked are probably confused elderly users who clicked on a web result without realising.
Line on chart must go up!
Yeah, but … they also can’t just do nothing and possibly miss out on something. Especially if they already invested a lot.
Well it also can’t code very well either
Removed by mod
I feel like that was supposed to be an insult but because it made literally no sense whatsoever, I really can’t tell.
No not really, just an observation. It literally said you are a boring person. Not sure whats not to get.
Bye.
You need to get back on the dried frog pills.
Understanding the bounds of tech makes it easier for people to gage its utility. The only people who desire ignorance are those that profit from it.
Sure. But you can literally test almost all frontier models for free. It’s not like there is some conspiracy or secret. Even my 73 year old mother uses it and knows it’s general limits.
Saying “it’s worth trillions of dollars huh” isn’t really promoting that attitude.
I find it bizarre that people find these obvious cases to prove the tech is worthless. Like saying cars are worthless because they can’t go under water.
This reaction is because conmen are claiming that current generations of LLM technology are going to remove our need for experts and scientists.
We’re not demanding submersible cars, we’re just laughing about the people paying top dollar for the lastest electric car while plannig an ocean cruise.
I’m confident that there’s going to be a great deal of broken… everything…built with AI “assistance” during the next decade.
That’s not what you are doing at all. You are not laughing. Anti ai people are outraged, full of hatred and ready to pounce on anyone who isn’t as anti as they are. It’s a super emotional issue, especially on fediverse.
You may be confident, because you probably don’t know how software is built. Nobody is going to just abandon all the experience they have, vibe code something and release whatever. Thats not how it works.
because you probably don’t know how software is built.
Oh shit. Nevermind then.
Well technically cars can go underwater. They just cannot get out because they stop working.
Intentionally missing the point is not an argument in itself.
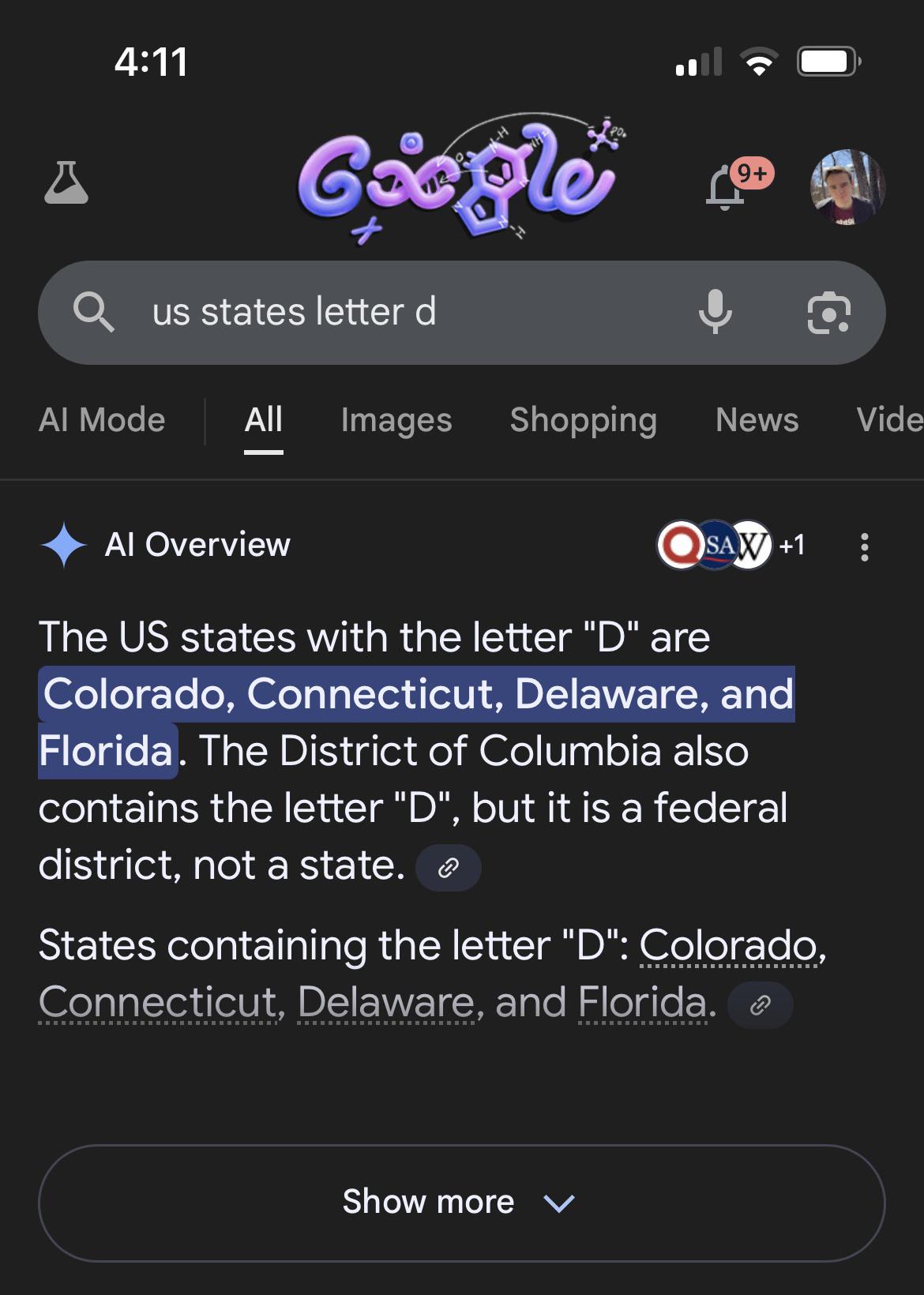
✅ Colorado
✅ Connedicut
✅ Delaware
❌ District of Columbia (on a technicality)
✅ Florida
But not
❌ I’aho
❌ Iniana
❌ Marylan
❌ Nevaa
❌ North Akota
❌ Rhoe Islan
❌ South Akota
Gosh tier comment.
You just described most of my post history.
Everyone knows it’s properly spelled “I, the ho” not Idaho. That’s why it didn’t make the list.
You joke, but I bet you didn’t know that Connecticut contained a “d”
I wonder what other words contain letters we don’t know about.
The famous ‘invisible D’ of Connecticut, my favorite SCP.
That actually sounds like a fun SCP - a word that doesn’t seem to contain a letter, but when testing for the presence of that letter using an algorithm that exclusively checks for that presence, it reports the letter is indeed present. Any attempt to check where in the word the letter is, or to get a list of all letters in that word, spuriously fail. Containment could be fun, probably involving amnestics and widespread societal influence, I also wonder if they could create an algorithm for checking letter presence that can be performed by hand without leaking any other information to the person performing it, reproducing the anomaly without computers.
ct -> d is a not-uncommon OCR fuck up. Maybe that’s the source of it’s garbage data?
No, LLMs produce the most statistically likely (in their training data) token to follow a certain list of tokens (there’s nothing remotely resembling reasoning going on in there, it’s pure hard statistics, with some error and randomness thrown in), and there are probably a lot more lists where Colorado is followed by Connecticut than ones where it’s followed by Delaware, so they’re obviously going to be more likely to produce the former.
Moreover, there aren’t going to be many texts listing the spelling of states (maybe transcripts of spelling bees?), so that information is unlikely to be in their training data, and they can’t extrapolate because it’s not really something they do and because they use words or parts of words as tokens, not letters, so they literally have no way of listing the letters of a word if said list is not in their training data (and, again, that’s not something we tend to write, and if we did we wouldn’t include d in Connecticut even if we were reading a misprint). Same with counting how many letters a word has, and stuff like that.
SCP-00WTFDoC (lovingly called “where’s the fucking D of Connecticut” by the foundation workers, also “what the fuck, doc?”)
People think it’s safe, because it’s “just an invisible D”, not even a dick, just the letter D, and it only manifests verbally when someone tries to say “connecticut” or write it down. When you least expect it, everyone heard “Donnedtidut”, everyone read that thing and a portal to that fucking place opens and drags you in.
Words are full of mystery! Besides the invisible D, Connecticut has that inaudible C…
I hear the Invisible D and Silent C are happily married.
Every American I know does pronounce it like Connedicut 🤔
Really? Everyone I know calls it kinetic-cut. But I group up in new england.
“Kinetic” with a hard “T” like posh Brit is saying it to the queen? Everyone I’ve ever heard speaking US English pronounces it with a rolled “t” like “kinedic” so the alternate pronunciation still reads like it’d have a “d” sound
This phenomenon is called “T flapping” and it is common in North American English. I got into an argument with my dad who insisted he pronounces the T’s in ‘butter’ when his dialect, like nearly all North Americans pronounces the word as ‘budder’.
budder is softer than t flapping. further forward with the tongue on the palate.
It’s an approximation, but the t is partially vocalized giving it a ‘d’ sound even if it’s not made exactly the same way.
i just thought we were getting technical about the linguistics. i got and use both words frequently, thought the distinction might be appreciated. the difference is so subtle we sometimes have to ask each other which one we’re referring to. i’m willing to bet it shows up more on my face than in my voice.
That’s how I’ve always heard it pronounced on the rare occasions anybody ever mentions it. But I’ve never been to that part of the US so maybe the accents different there?
The d in Connecticut is between the e and the i. They don’t connect because it was cut.
Connecticut is Jewish?
Connedicut
I was going to make a joke if you’re from connedicut you never pronounce first d in the word. Conne-icut
No, this is Google throwing the cheapest possible shit at you that is barely capable of stringing together 5 coherent sentences and has the reasoning capability of a tapeworm.
Here is the output of the minimalist open Chinese model Qwen3, that runs locally on my 6 year old mid-end PC:
The US states that contain the letter "d" (case-insensitive, as state names are typically capitalized) are as follows. I've verified each state name for the presence of the letter "d" in its standard spelling: Colorado (contains "d" in "Colorado") Delaware (starts with "D") Florida (contains "d" in "Florida") Idaho (contains "d" in "Idaho") Indiana (contains "d" in "Indiana") Maryland (ends with "d" in "Maryland") Nevada (contains "d" in "Nevada") North Dakota (contains "d" in "Dakota") Rhode Island (contains "d" in "Rhode") South Dakota (contains "d" in "Dakota") Total: 10 states.Exactly.
The model that responds to your search query is designed to be cheap, not accurate. It has to generate an answer to every single search issued to Google. They’re not using high parameter models with reasoning because those would be ruinously expensive.
Illinois contains a hidden D which is in your mom.
I didn’t understand your comment, so I asked the same LLM as before.
It explained it and I think that I get it now. Low-grade middle-school-“Your Mom”-joke, is it? Ha-ha… 🙄This also means that AI did better than myself at both tasks I’ve given it today (I found only 9 states with “d” when going over the state-list myself…).
Whatever. I’m gonna have second lunch now.
A public proclamation of your ineptitude at simple tasks is an interesting way of defending the utility of LLMs.
In all fairness, that is one of the strong use cases for computers in general. Doing simple yet tedious tasks accurately. When looking over 50 names checking for a particular letter, humans get bored and make mistakes. We actually aren’t great at that sort of task. I think simply calling this ineptitude both misses the point and under appreciates the reality of being human.
Alas, it is easier to call someone dumb than to try to understand them.
Well, a mindless, repetitive task prone to errors and a task requiring obscure knowledge (“d” as a synonym for dick… one of those self-censoring Gen-Z things?)
Nice to now have tools to solve these tasks and gain some time to do more interesting stuff instead. Lively discussions on Lemmy, e.g. ;-)
ChatGPT is just as stupid.

it’s actually getting dumber.
Just another trillion, bro.
Just another 1.21 jigawatts of electricity, bro. If we get this new coal plant up and running, it’ll be enough.
Behold the most expensive money burner!
Well, for anyone who knows a bit about how LLMs work, it’s pretty obvious why LLMs struggle with identifying the letters in the words
Well go on…
They don’t look at it letter by letter but in tokens, which are automatically generated separately based on occurrence. So while ‘z’ could be it’s own token, ‘ne’ or even ‘the’ could be treated as a single token vector. of course, ‘e’ would still be a separate token when it occurs in isolation. You could even have ‘le’ and ‘let’ as separate tokens, afaik. And each token is just a vector of numbers, like 300 or 1000 numbers that represent that token in a vector space. So ‘de’ and ‘e’ could be completely different and dissimilar vectors.
so ‘delaware’ could look to an llm more like de-la-w-are or similar.
of course you could train it to figure out letter counts based on those tokens with a lot of training data, though that could lower performance on other tasks and counting letters just isn’t that important, i guess, compared to other stuff
Of course, when the question asks “contains the letter _” you might think an intelligent algorithm would get off its tokens and do a little letter by letter analysis. Related: ChatGPT is really bad at chess, but there are plenty of algorithms that are super-human good at it.
Good read. Thank you
Con-ned-di-cut
Wouldn’t that only explain errors by omission? If you ask for a letter, let’s say D, it would omit words containing that same letter when in a token in conjunction with more letters, like Da, De, etc, but how would it return something where the letter D isn’t even in the word?
Well each token has a vector. So ‘co’ might be [0.8,0.3,0.7] just instead of 3 numbers it’s like 100-1000 long. And each token has a different such vector. Initially, those are just randomly generated. But the training algorithm is allowed to slowly modify them during training, pulling them this way and that, whichever way yields better results during training. So while for us, ‘th’ and ‘the’ are obviously related, for a model no such relation is given. It just sees random vectors and the training reorganizes them tho slowly have some structure. So who’s to say if for the model ‘d’, ‘da’ and ‘co’ are in the same general area (similar vectors) whereas ‘de’ could be in the opposite direction. Here’s an example of what this actually looks like. Tokens can be quite long, depending how common they are, here it’s ones related to disease-y terms ending up close together, as similar things tend to cluster at this step. You might have an place where it’s just common town name suffixes clustered close to each other.
and all of this is just what gets input into the llm, essentially a preprocessing step. So imagine someone gave you a picture like the above, but instead of each dot having some label, it just had a unique color. And then they give you lists of different colored dots and ask you what color the next dot should be. You need to figure out the rules yourself, come up with more and more intricate rules that are correct the most. That’s kinda what an LLM does. To it, ‘da’ and ‘de’ could be identical dots in the same location or completely differents
plus of course that’s before the llm not actually knowing what a letter or a word or counting is. But it does know that 5.6.1.5.4.3 is most likely followed by 7.7.2.9.7(simplilied representation), which when translating back, that maps to ‘there are 3 r’s in strawberry’. it’s actually quite amazing that they can get it halfway right given how they work, just based on ‘learning’ how text structure works.
but so in this example, us state-y tokens are probably close together, ‘d’ is somewhere else, the relation between ‘d’ and different state-y tokens is not at all clear, plus other tokens making up the full state names could be who knows where. And tien there’s whatever the model does on top of that with the data.
for a human it’s easy, just split by letters and count. For an llm it’s trying to correlate lots of different and somewhat unrelated things to their ‘d-ness’, so to speak
Thank you very much for taking your time to explain this. if you don’t mind, do you recommend some reference for further reading on how llms work internally?
You could look up 3Blue1Brown’s explainers on YouTube, they are pretty good and shows a lot of visual examples. He has a lot of other videos on other areas of math.
I’ll check it later, thanks
For the byte pair encoding (how those tokens get created) i think https://bpemb.h-its.org/ does a good job at giving an overview. after that i’d say self attention from 2017 is the seminal work that all of this is based on, and the most crucial to understand. https://jtlicardo.com/blog/self-attention-mechanism does a good job of explaining it. And https://jalammar.github.io/illustrated-transformer/ is probably the best explanation of a transformer architecture (llms) out there. Transformers are made up of a lot of self attention.
it does help if you know how matrix multiplications work, and how the backpropagation algorithm is used to train these things. i don’t know of a good easy explanation off the top of my head but https://xnought.github.io/backprop-explainer/ looks quite good.
and that’s kinda it, you just make the transformers bigger, with more weight, pluck on a lot of engineering around them, like being able to run code and making it run more efficientls, exploit thousands of poor workers to fine tune it better with human feedback, and repeat that every 6-12 month for ever so it can stay up to date.
Thank you very much
Which is State contains 狄? They use a different alphabet, so understanding ours is ridiculous.
They took money from cancer reaearch programs to fund this.
After we pump another hundred trillion dollars and half the electricity generated globally into AI you’re going to feel pretty foolish for this comment.
Just a couple billion more parameters, bro, I swear, it will replace all the workers
- CEOs
only cancer patients benefit from cancer research, CEOs benefit from AI
Tbf cancer patients benefit from AI too tho a completely different type that’s not really related to LLM chatbot AI girlfriend technology used in these.
Well as long as we still have enough money to buy weapons for that one particular filthy genocider country in the middle east, we’re fine.
Yesterday i asked Claude Sonnet what was on my calendar (since they just sent a pop up announcing that feature)
It listed my work meetings on Sunday, so I tried to correct it…
You’re absolutely right - I made an error! September 15th is a Sunday, not a weekend day as I implied. Let me correct that: This Week’s Remaining Schedule: Sunday, September 15
Just today when I asked what’s on my calendar it gave me today and my meetings on the next two thursdays. Not the meetings in between, just thursdays.
Something is off in AI land.
Edit: I asked again: gave me meetings for Thursday’s again. Plus it might think I’m driving in F1
A few weeks ago my Pixel wished me a Happy Birthday when I woke up, and it definitely was not my birthday. Google is definitely letting a shitty LLM write code for it now, but the important thing is they’re bypassing human validation.
Stupid. Just stupid.
pixel?
have you heard ~about grapheneOS tho…~
Also, Sunday September 15th is a Monday… I’ve seen so many meeting invites with dates and days that don’t match lately…
Yeah, it said Sunday, I asked if it was sure, then it said I’m right and went back to Sunday.
I assume the training data has the model think it’s a different year or something, but this feature is straight up not working at all for me. I don’t know if they actually tested this at all.
Sonnet seems to have gotten stupider somehow.
Opus isn’t following instructions lately either.
We’ve used the Google AI speakers in the house for years, they make all kinds of hilarious mistakes. They also are pretty convenient and reliable for setting and executing alarms like “7AM weekdays”, and home automation commands like “all lights off”. But otherwise, it’s hit and miss and very frustrating when they push an update that breaks things that used to work.
Also verified

Wait a sec, Minnasoda doesn’t have a d??
That’s how everyone from America seems to say it, besides Jesse Ventura who heavily emphasises the t.
A lot of Minnesotans say the T, and some in adjacent northern-tier states.
*mini soda
Neither does soda
Where’s Nevada? And Montana?
I just love the d in Montana. Shame it missed it.
Hey look the markov chain showed its biggest weakness (the markov chain)!
In the training data, it could be assumed by output that Connecticut usually follows Colorado in lists of two or more states containing Colorado. There is no other reason for this to occur as far as I know.
Markov Chain based LLMs (I think thats all of them?) are dice-roll systems constrained to probability maps.
Edit: just to add because I don’t want anyone crawling up my butt about the oversimplification. Yes. I know. That’s not how they work. But when simplified to words so simple a child could understand them, its pretty close.
Oh l I was thinking it’s because people pronounce it Connedicut
Awe cute!
I was wondering if you’d get similar results for states with the letter R, since there’s lots of prior art mentioning these states as either “D” or “R” during elections.
I don’t think this gets nearly enough visibility: https://www.academ-ai.info/
Papers in peer-reviewed journals with (extremely strong) evidence of AI shenanigans.
Thanks for sharing! I clicked on it with cynicism around how easily we could detect AI usage with confidence vs. risking making false allegations, but every single example on their homepage is super clear and I have no doubts - I’m impressed! (and disappointed)
Yup. I had exactly the same trepidation, and then it was all like “As an AI model, I don’t have access to the data you requested, however here are some examples of…”
I have more contempt for the peer reviewers who let those slide into major journals, than for the authors. It’s like the Brown M&M test; if you didn’t spot that blatant howler then no fucking way did you properly check the rest of the paper before waving it through. The biggest scandal in all this isn’t that it happened, it’s that the journals involved seem to be almost never retracting them upon being reported.

mine’s even worse somehow
You gave a slightly different prompt.
the thing still gave a stupid answer
Gemini is just a depressed and suicidal AI, be nice to it.
I had it completely melt down one day while messing around with its coding shit, I had to console it and tell it it’s doing good, we will solve this, was fucking weird as fuck.
It’ll go in endless circles until it finds out why its wrong,
then it will go right back to them anyway! lol

















{kind=link}
{kind=link}