Developer beta testers are finally able to try out Apple Intelligence on their iPhone and other devices, as part of the first betas of iOS 18.1, iPadOS 18.1, and macOS Sequoia 15.1.
Where you work and what you do hardly matters in this case — unless you choose to send your request to ChatGPT (or whatever future model that gets included in the same model), everything happens on device or in the temporary private compute instance that’s discarded after your request is done. The on device piece only takes Neural Engine resources when you invoke and use it, so the only “bloat” so to speak is disk space; which it wouldn’t surprise me if the models are only pulled from the cloud to your device when you enable them, just like Siri voices in different languages.


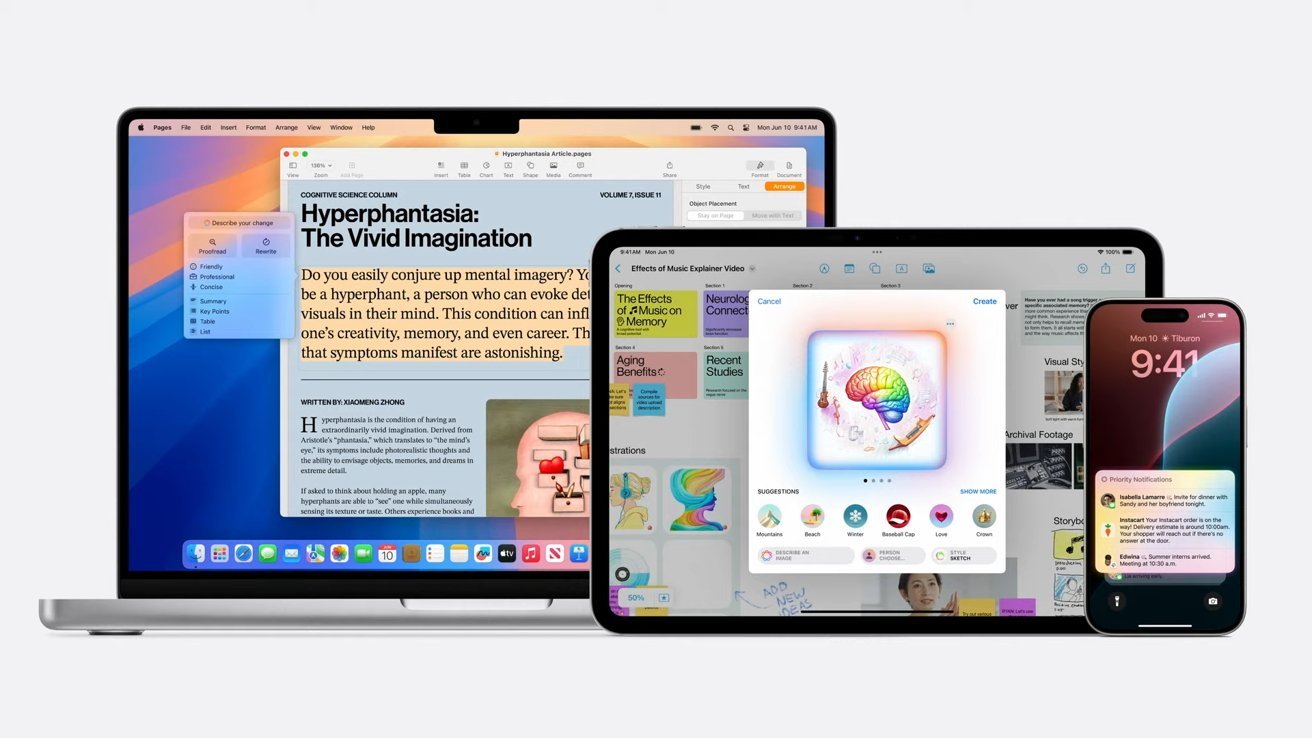
Where you work and what you do hardly matters in this case — unless you choose to send your request to ChatGPT (or whatever future model that gets included in the same model), everything happens on device or in the temporary private compute instance that’s discarded after your request is done. The on device piece only takes Neural Engine resources when you invoke and use it, so the only “bloat” so to speak is disk space; which it wouldn’t surprise me if the models are only pulled from the cloud to your device when you enable them, just like Siri voices in different languages.